
If you’re an IT expert, you know databases are the building blocks of tech, right? But even the best of us can sometimes get tangled up in the details. We’re going to dive into one of those little complexities that can cause big headaches if not appropriately understood: functional dependencies in database systems.
Let’s say you have a bunch of information about your clients, like their IDs, names, and the services they use. Functional dependencies help you link all that data in a way that makes sense. So, if you know a client’s ID, you should be able to find their name and services without any confusion or contradictions. When your data’s in good shape, everything from software testing to API integrations runs smoother.
Speaking of API development, you can use work automation software like Wrike to track the progress of your API integration projects. You can monitor dependencies between your application and third-party services and keep an eye on milestones.
Track functional dependencies with Wrike — start your free trial now.
So, stick around, and we’ll walk you through what functional dependencies are, why they’re important, and how to spot them.
Introduction to functional dependencies
A functional dependency is a relationship between two sets of attributes in a database table. It describes how the value of one attribute determines the value of another attribute.
Basically, a functional dependency is represented as X → Y, where X and Y are sets of attributes. This notation implies that any two rows in the table with the same value for X will also have the same value for Y. In other words, the value of Y is functionally dependent on the value of X.
Let’s consider an example to illustrate functional dependencies. Suppose we have a table called “Employees” with attributes such as employee ID, name, department, and salary. If we define a functional dependency as “department → salary,” it means that for any two employees who belong to the same department, their salaries will be the same. This allows us to infer the salary of an employee based on their department alone.
It’s important to note that functional dependencies can exist between multiple attributes as well. For instance, we could have a functional dependency like “department, position → salary,” which means that the salary of an employee is determined not only by their department but also by their position within that department.
Importance of functional dependencies in database systems
Functional dependencies are vital for maintaining data integrity and minimizing redundancy in a database system. When we have a functional dependency between two attributes, we only need to store one, as the other can be derived from the first. This reduces storage requirements and improves overall database efficiency. It also allows us to enforce data integrity constraints to prevent data inconsistencies and verify the accuracy of query results.
Custom fields in Wrike can act similarly to functional dependencies in a database. Just like functional dependencies help organize data within databases, custom fields help manage and track specific data points within your projects. For instance, you could create a custom field for project IDs, which links to specific tasks, deliverables, or milestones. This setup ensures that each piece of your project is uniquely identified and directly traceable to its source, minimizing confusion and redundancy.

Key terms in functional dependencies
Now that you understand the basics, let’s delve deeper into the theory behind functional dependencies. Here are the basic concepts and terminologies:
- Candidate key: This signifies a minimal set of attributes that uniquely identify each row in a table, which is essential for data retrieval and integrity.
- Superkey: This represents any set of attributes that includes a candidate key. It is a broader concept encompassing multiple attributes that can uniquely identify rows in a table, which assists in understanding how we can identify data in a table.
- Closure: This is the process of determining all the functional dependencies in a table and which ones need to be preserved. It involves analyzing the relationships between attributes and identifying the dependencies that exist.
- Transitive dependency: This occurs when the value of one attribute determines the value of another indirectly through a chain of functional dependencies. It is a concept that helps us understand how attributes are related and how changes in one attribute can affect others.
Types of functional dependencies
Here are the three main types of functional dependencies:
Trivial functional dependencies
Trivial functional dependencies are those that can be inferred based on the definition of the attribute itself. These dependencies are straightforward and do not provide any new information about the relationships between attributes.
Partial functional dependencies
Partial functional dependencies arise when an attribute depends on only part of a candidate key. In other words, the attribute is functionally dependent on a subset of the candidate key attributes.
Transitive functional dependencies
Transitive functional dependencies occur when the value of one attribute determines the value of another attribute indirectly through another attribute. This type of dependency can be identified when there is a chain of dependencies between attributes.
Functional dependencies and database design
To fully understand the importance of functional dependencies, let’s discuss their role in normalization and their impact on database schema design.
Role of functional dependencies in normalization
Normalization is a technique used to eliminate data redundancy and ensure data consistency in a database. It involves breaking down a table with complex dependencies into multiple smaller tables. This process helps improve database performance and reduces the chances of data inconsistencies.
With functional dependencies, you can:
- Define how different pieces of data are related and organize data effectively
- Identify the key attributes of data tables and ensure each record in a table is unique and easily retrievable
- Define the data’s integrity, ensuring it remains accurate and consistent over time
- Eliminate redundancy and prevent the same piece of information from being stored in multiple places
- Improve query performance more efficiently and improve the performance of database systems
- Facilitate database design process, ensuring that databases are structured logically
- Simplify the data structure and make it more logical
Impact on database schema design
Database schema design heavily relies on functional dependencies. They can help determine the appropriate structure for organizing the attributes and tables in a database. By identifying the right attributes and relationships between them, IT experts can create a database that is easier to maintain and update.
Functional dependencies also play a role in determining the primary key and foreign key relationships between tables. The primary key of a table is determined by the attributes on which other attributes depend. This key is then used as a reference in different tables, establishing the necessary relationships between them. This way, IT experts can establish the correct primary key and foreign key relationships, ensuring data consistency and integrity.
Practical applications of functional dependencies
Now that we’ve covered the theoretical aspects, let’s explore some real-world applications of functional dependencies and how you can use powerful automation software like Wrike to eliminate complexities in the IT industry.
Database design and optimization
If you want to set up a new customer relationship management (CRM) system database, you need to ensure there’s exactly one set of contact info for every customer ID. This is the core of functional dependencies — preventing duplicate records or inconsistent data.
Wrike’s custom item types can be a lifesaver when setting up a new database system. Create a customizable library that matches your business processes and makes it easier to store all the specific info you need.

Network design
Functional dependencies define how IP addresses are allocated within subnets. Each subnet mask (like 255.255.255.0) corresponds to a specific range of IP addresses. Understanding this relationship helps in planning network layouts efficiently, reducing conflicts, and ensuring reliable connectivity.
Data migration
Let’s say you’re moving data from an old system to a new one. Here, functional dependencies ensure that relationships between data are preserved. For example, employee IDs must match up with the correct department codes. Keeping these dependencies straight means fewer errors and a smoother transition.
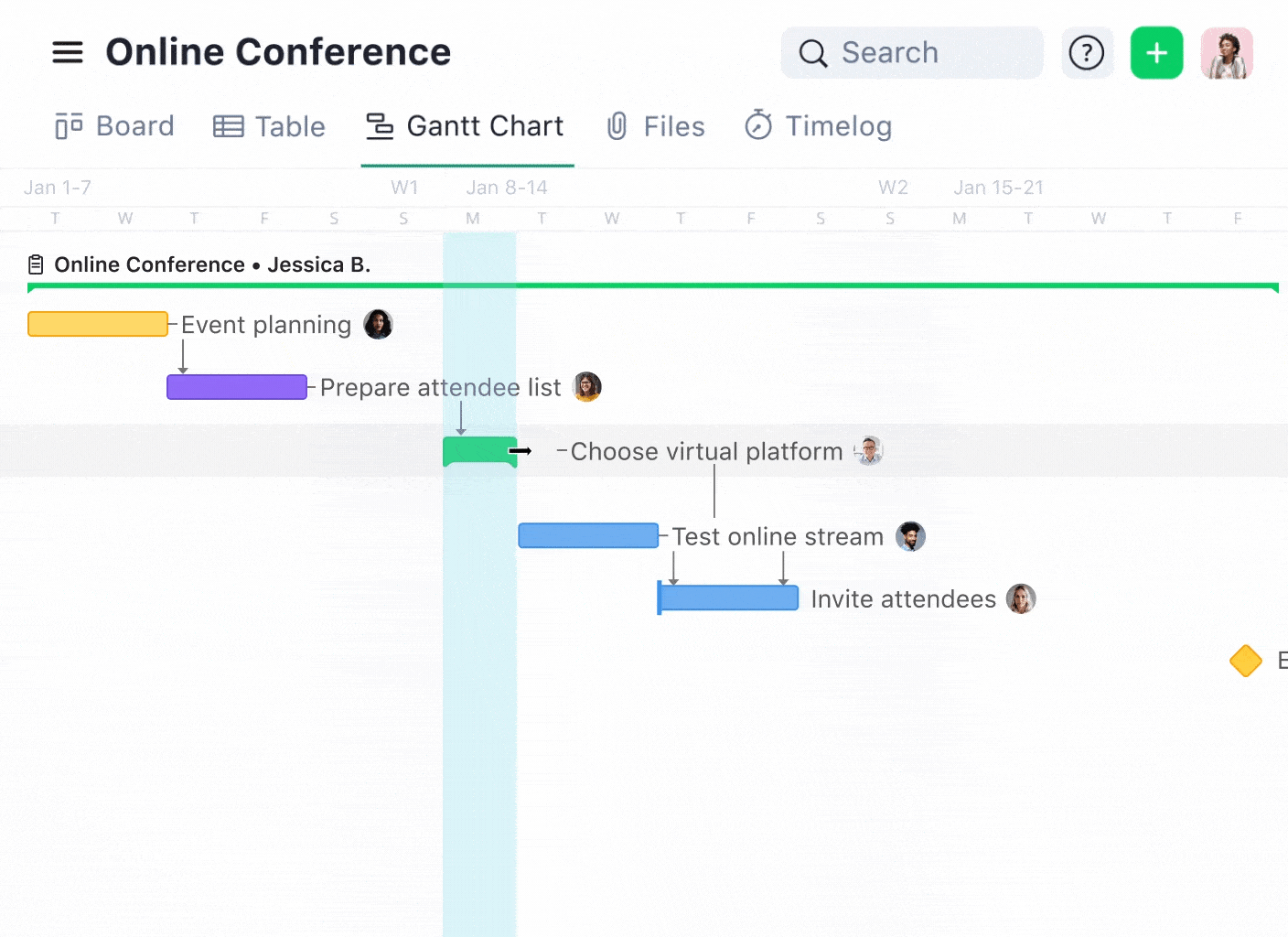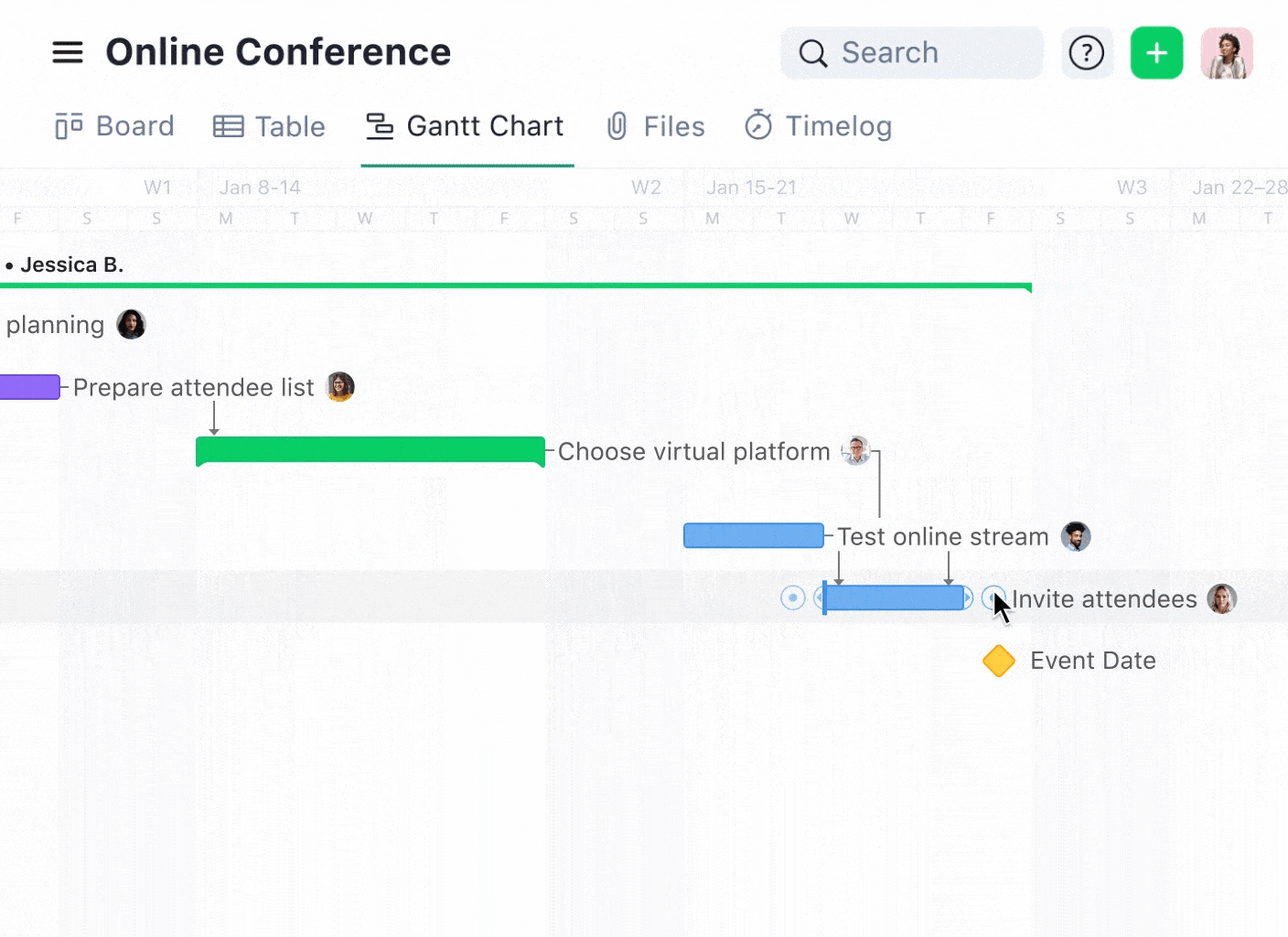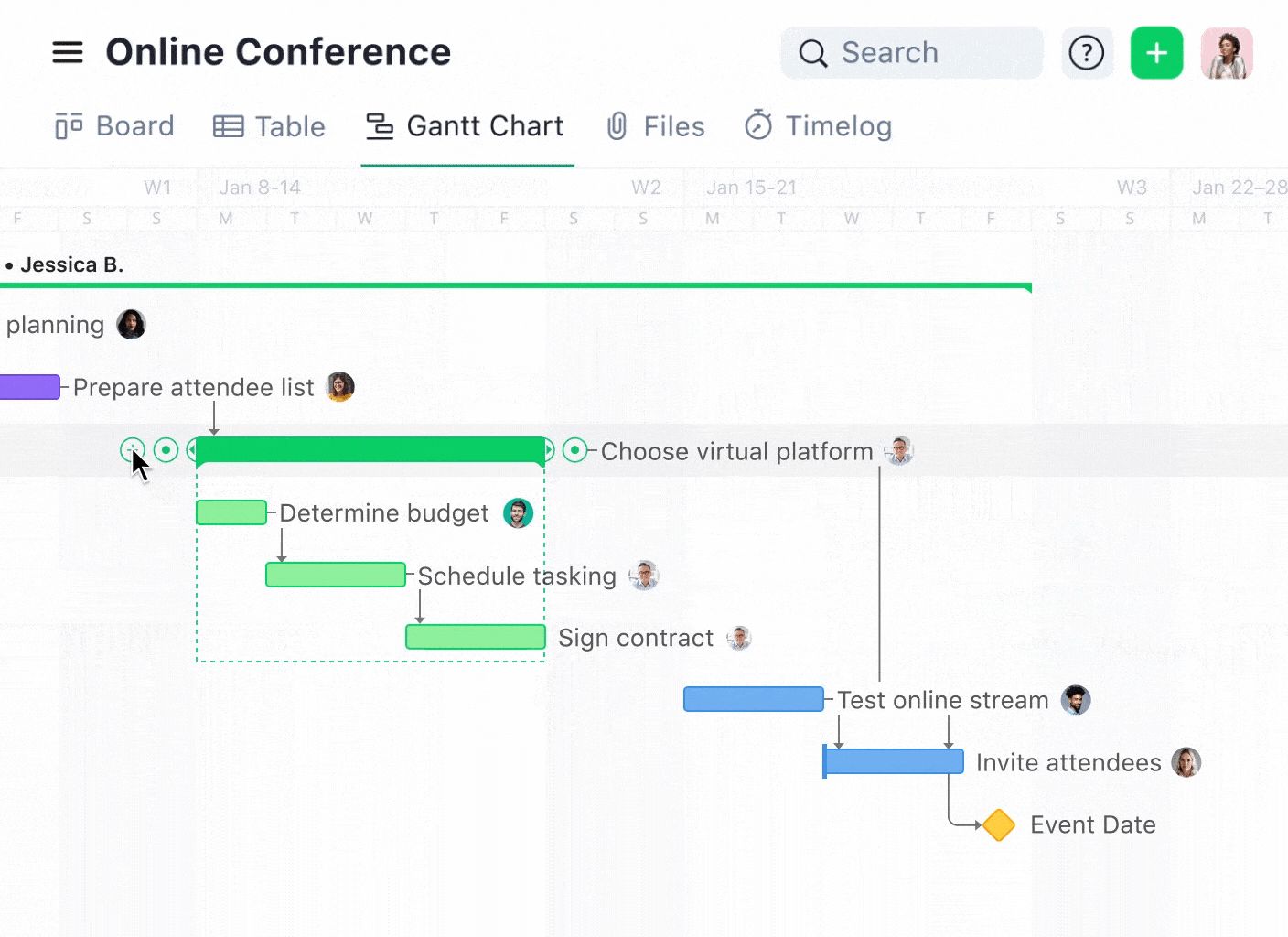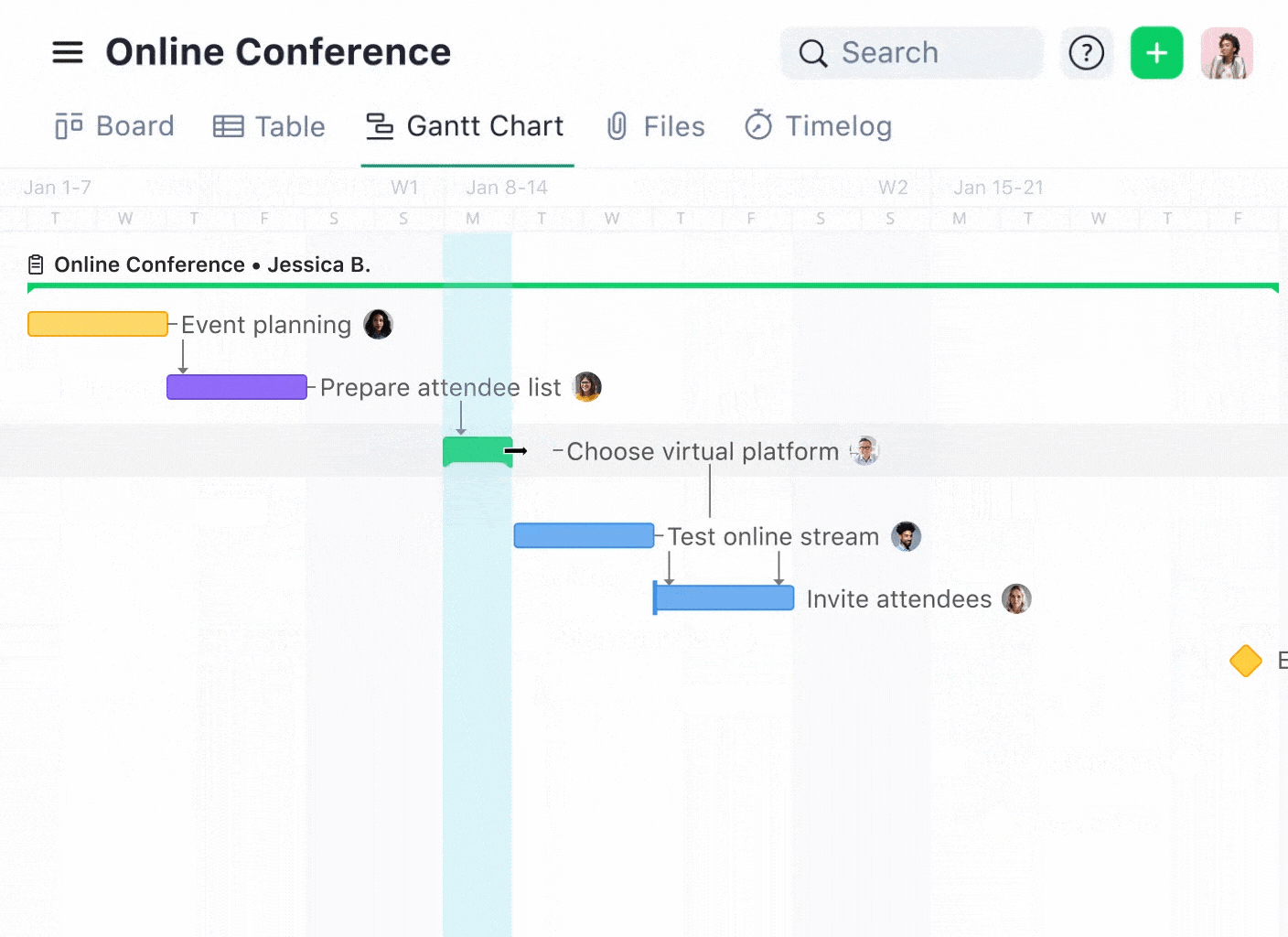
During data migration, you can use a Gantt chart to visualize the migration process and map out dependencies between different project stages. This visual aid helps plan and execute the migration smoothly, ensuring that each piece of data lands in the right place at the right time.
Security policy implementation
In cybersecurity, enforcing access control policies involves functional dependencies. A user’s role (administrator) determines their access level. This clear-cut relationship ensures that only the right people can access sensitive data or systems. Getting this right keeps systems secure and prevents unauthorized access nightmares.
With Wrike’s enterprise-grade security, you can set up specific access roles to ensure the right people have access to the right information.Best practices for handling functional dependencies
Regularly reviewing and updating the functional dependencies in the database is essential. As the database evolves and new attributes or relationships are introduced, you must reassess your existing dependencies and make necessary adjustments. Here are some of the best practices you should follow:
- Start with the basics. Don’t overcomplicate your data models or systems.
- Write down your functional dependencies and how they interact.
- Always ensure that your functional dependencies support the accuracy and consistency of your data.
- Make sure everyone understands what functional dependencies are and why they matter.
- Use the right work automation software to help visualize and manage dependencies.
- Make it a habit to regularly review and update your understanding of functional dependencies in your projects.
- Before implementing changes, test how they affect your functional dependencies and overall system.
How to use Wrike to manage functional dependencies
You can effectively manage functional dependencies in database systems by leveraging the right software tools. If you’re overseeing a software development project, task dependencies on Wrike’s Gantt chart help manage the sequence of development phases, e.g., Design → Development → Testing → Deployment.
Here, each phase’s start depends on the completion of the previous one, mirroring functional dependencies in database design where certain conditions must be met before moving to the next step.
During data migration, you can communicate with your team about dependencies. Whether it’s through comments on tasks, @mentions, or shared dashboards, everyone stays in the loop. You can even sync with tools like Jira, GitHub, or Salesforce, linking code and sprint tasks.
Patrick O’Connor, Manager of Professional Services for Data Migration at BigCommerce, says:
“I can quickly see what people have been working on in Wrike today and which projects got pushed back. We’re also building a Salesforce connector so we can automatically kick off projects with a blueprint and push Wrike updates into Salesforce. We’re also building a Jira connector to share when tickets are opened or completed.”
Ready to optimize your IT processes and manage your database system effectively? Start your two-week free trial right away.
Note: This article was created with the assistance of an AI engine. It has been reviewed and revised by our team of experts to ensure accuracy and quality.



